Characterizing the Structure of English Sentences by Examining How a Language Model Makes Its Predictions
Table of Contents
- Motivation
- Background: Feature Interactions
- How
ArchipelagoDetects Feature Interactions - Using
Archipelagoto Examine a Language Model - Conclusion
- Footnotes
Motivation
Why does a language model make the predictions it does? Suppose you were asked to predict the next word in this sentence:
yesterday my buddies and I stayed up all night watching the
What would you choose? Take a moment and think. The GPT-2 language model predicts these as the twenty most likely next words:
news game new first Super sun movie final World latest last games big show sunset fireworks Olympics NFL sunrise NBA
Most likely, many of these were the same predictions that you thought of. Indeed, modern language models have gotten so good that they are often indistinguishable from human performance. Because language models so closely approximate human performance, understanding why language models make the predictions they do will also tell us about how humans predict subsequent words in a sentence. It can help us characterize the structure of language. In this post, we will first examine the concept of feature interactions, and then we will use them to explain how language models make the predictions that they do.
Background: Feature Interactions
Every effective machine learning model must learn an accurate, generalizable mapping from its inputs to a prediction. For many problems, a linear combination of the input features is insufficient. A model must instead focus on learning complex interactions between these features. A great way to understand a trained model is thus by examining the feature interactions that it has learned, and which it uses to make predictions.
Tsang et al. 1 recently developed Archipelago, a method to discover the feature interactions a model has learned. We will first examine its core ideas, and then apply it to the GPT-2 language model.
Archipelago starts by detecting all pairs of inputs (a, b) which “interact.” Intuitively, this means that the effect on the model’s prediction of seeing a and b together is different than the effect of only seeing a added to the effect of only seeing b. More formally, we might say that a and b exhibit a positive interaction when
f(a, b) > f(a, _) + f(_, b)
where _ is a baseline value representing an absence of signal. However, this equation is not quite right. To see why, imagine that we are predicting a person’s height based on two features a and b. Suppose that
f(a, b) = 8
f(a, _) = 4
f(_, b) = 4
In this case, we inituitively feel that a and b exhibit a strong positive interaction. Alone, they each predict that the person is very short, while taken together they predict that the person is very tall. However, f(a, b) = f(a, _) + f(_, b) = 8 which indicates no interaction. This discrepancy is due to fact that our model’s baseline prediction is f(_, _) = 5.5 (roughly the average human height). This baseline prediction is included once on the left side of the equation, but twice on the right. We can thus fix our equation by subtracting it like so:
f(a, b) > f(a, _) + f(_, b) - f(_, _)
We can also re-arrange this equation as follows to get a different perspective on what a feature interaction represents:
f(a, b) - f(_, b) > f(a, _) + f(_, _)
Intuitively, this means that observing feature a in the presence of feature b has a different effect on the model’s prediction than the effect of seeing feature a in the presence of the baseline. Tsang et al. provide this helpful visualization:
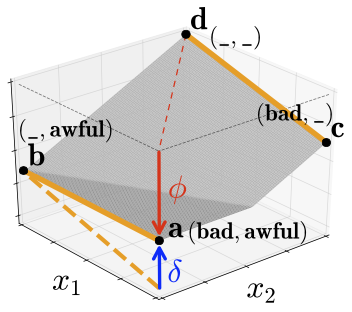
Here, we are trying to predict the sentiment of the sentence bad, awful. Observe that seeing bad in the context of the baseline (f(bad, _) - f(_, _)) has a strong negative effect, whereas seeing bad in the context of awful (f(bad, awful) - f(_, awful)) has a neutral effect, since the sentiment of the sentence is already negative, and adding bad does not change it much. Thus we conclude that
f(bad, awful) - f(_, awful) > f(bad, _) - f(_, _)
which demonstrates that bad and awful exhibit a positive interaction. We now have two equivalent ways to conceptualize an interaction between a pair of features:
f(a, b) > f(a, _) + f(_, b) - f(_, _). The effect of seeingaandbtogether is greater than the sum of the effects of seeing them individually,f(a, b) - f(_, b) > f(a, _) + f(_, _). Th effect of seeingain the context ofbis different than the effect of seeingaalone.
How Archipelago Detects Feature Interactions
Tsang et al. implement this concept in Archipelago, an open-source tool. Archipelago finds the k strongest pairwise feature interactions, where k is specified by the user. It merges overlapping pairs into one set. For example, if k=2 and Archipelago detects (a,b) and (b,c) as the strongest pairwise interactions, is will output one set (a,b,c). For each of these merged sets, Archipelago computes its overall effect on the prediction. It does this by removing the set from the input, and measuring how much the model’s prediction changes. For example, suppose we have a model predicting the sentiment of the sentence “this movie was very bad.” To quantify the importance of the set {“very”, “bad”}, Archipelago tests what happens when you remove it from the sentence, and replace it with baseline tokens. It does this in two ways, and reports the average: f("this movie was very bad") - f("this movie was _ _"), and f("_ _ _ very bad") - f("_ _ _ _ _").
Using Archipelago to Examine a Language Model]
Archipelago works with many typies of models. For sequential models, Tsang et al. focus on the task of sentiment analysis. I grew interested in applying Archipelago to a language model. As we will see, it is able to detect which set of input words are the most important for a particular prediction of the next word. This not only reveals what the language model has learned: because model language models are so accurate, it also characterizes the structure of sentences in a given language.
The Archipelago API works with any model, but only requires that you use a ModelWrapper to convert the inputs and outputs into a standardized format. In tha case of a sequential model, the inputs must be a list of tokens and the ouputs a list of logits. I downloaded the GPT-2 language model and used the following ModelWrapper:
class GPTWrapperTorch:
def __init__(self, model: Any) -> None:
self.model = model
def __call__(self, batch_ids: Iterable[Iterable[int]]) -> List[List[float]]:
# Input: tokens - shape = (batch_size, sent_len)
# Output: predictions for next word - shape = (batch_size, vocab_size)
preds = model(torch.LongTensor(batch_ids)).logits
next_word_preds = preds[:, -1] # Only keep predictions for last word
return next_word_preds.numpy()
Let’s now use Archipelago to explain GPT-2’s predictions for two sentences. Consider GPT-2’s top twenty predictions for the next word in this sentence:
Input: yesterday my buddies and I stayed up all night watching the
Output: news game new first Super sun movie final World latest last games big show sunset fireworks Olympics NFL sunrise NBA
The word “Super” corresponds to “Super Bowl,” and “World” to “World Series.” These indeed seem like logical predictions. We now use Archipelago to examine which feature interactions caused the model to predict “Super.” We choose k=6, meaning that Archipelago finds the top six pairwise interactions and merges them when possible. Dark blue indicates a strong positive interaction (meaning it makes the prediction more likely), while dark red indicates a strong negative interaction:

We also set k=0, in which case Archipelago simply checks how much each word contributed to the predictions using the two methods of baseline comparison outlined earlier:

We see that while most of “stayed”, “up”, “all”, “watching”, and “the” have an especially strong effect on their own (with the possible exception of “up”), taken together they produce a strong effect on the model’s prediction of “Super”. We can verify this by feeding this set on its own to GPT-2:
Input: _ _ _ _ _ stayed up all _ watching the
Output: _ news game show TV world movie games whole new “ tv last night first big sun World latest \
While the top twenty predictions no longer include “Super”, they contain very similar words such as “game”, “TV”, and “World” (for “World Series”). As we expect, none of these words individually would have such predictive power:
Input: _ _ _ _ _ _ _ _ _ _ the
Output: _ _- last first end rest - followings..ta / | name “ ‘t
This example illiustrates our first way of conceptualizing feature interactions: the effect of the set is greater than the sum of the effect of each part.
Let’s next consider this example:
Input: it is a shame that everyone hates macklemore. His music is so fucking
Output: good great dope catchy bad awesome amazing perfect beautiful cool
Running Archipelago with k=6 produces the following result:

This indeed matches with our intuition of the most important set of words that, taken together, predict the next one. Let’s now see what happens when we remove some of the individual words from this set:
Input: it is a _ that everyone hates macklemore. His music is so fucking
Output: bad good awful annoying stupid lame terrible boring dumb bland
Without the word “shame”, we have removed the speaker’s negation of the rest of that sentence. Thus nine out of ten of the model outputs are now words with a negative sentiment. Consider removing a different word in our set:
Input: it is a shame that everyone hates macklemore. _ music is so fucking
Output: good bad great stupid annoying boring dope lame awful hard
Once again, most of the output words are now negative (this time, seven out of ten). Removing “his” disconnects the second sentence from the first, leading the model to complete the sentence “music is so fucking”, which indeed seems to lead to a negative conclusion. We see that each word in the set truly is necessary: without its presence, the other words would have a different effect on the prediction. This nicely illustrates our second conception of feature interactions: the effect of one feature changes in the context of other features.
Conclusion
By analyzing a language model’s feature interactions with Archipelago, we have been able to understand why it is making its predictions. Modern language models are extremely effective, and hence must have learned a great deal about our language. Examining how they make predictions thus not only illustrates how the models work: it illustrates how language works. The examples we examined indeed match with our intuitions regarding which groups of words, taken together, are most important for predicting the next word in the sentence.
Archipelago is an expecially useful tool because it can be applied to any model. So long as the user ensure that the input and output are formatted correctly, Archipelago can probe it and shed light on how it makes predictions. I encourage the interested reader to use Archipelago to examine other types of models, such as Language Models, CNNs, and other sequential models.
Footnotes
-
Tsang, Michael, et al. “How Does This Interaction Affect Me? Interpretable Attribution for Feature Interactions.” ArXiv:2006.10965 [Cs, Stat], June 2020. arXiv.org, http://arxiv.org/abs/2006.10965. ↩